Data Ingestion
TabularML은 데이터 분석을 효율적으로 수행할 수 있도록 다양한 데이터 수집 및 처리 방식을 제공합니다.
데이터셋를 수집하는 과정은 SourceType(데이터 소스 선택) → PurposeType(분석 목적 선택) → 분석 방법 결정 순서로 진행됩니다

Source Type
데이터셋을 구성할 방법을 선택합니다.
데이터를 수집하는 방법으로는 File, DBMS, Datahub, NIFI를 지원합니다.
File
File을 선택하고 DropBox위로 파일을 드래그&드롭 해서 파일을 업로드합니다.

Database
- Database를 선택하고 데이터베이스의 주소, 포트를 포함하는 접속 정보를 입력합니다.
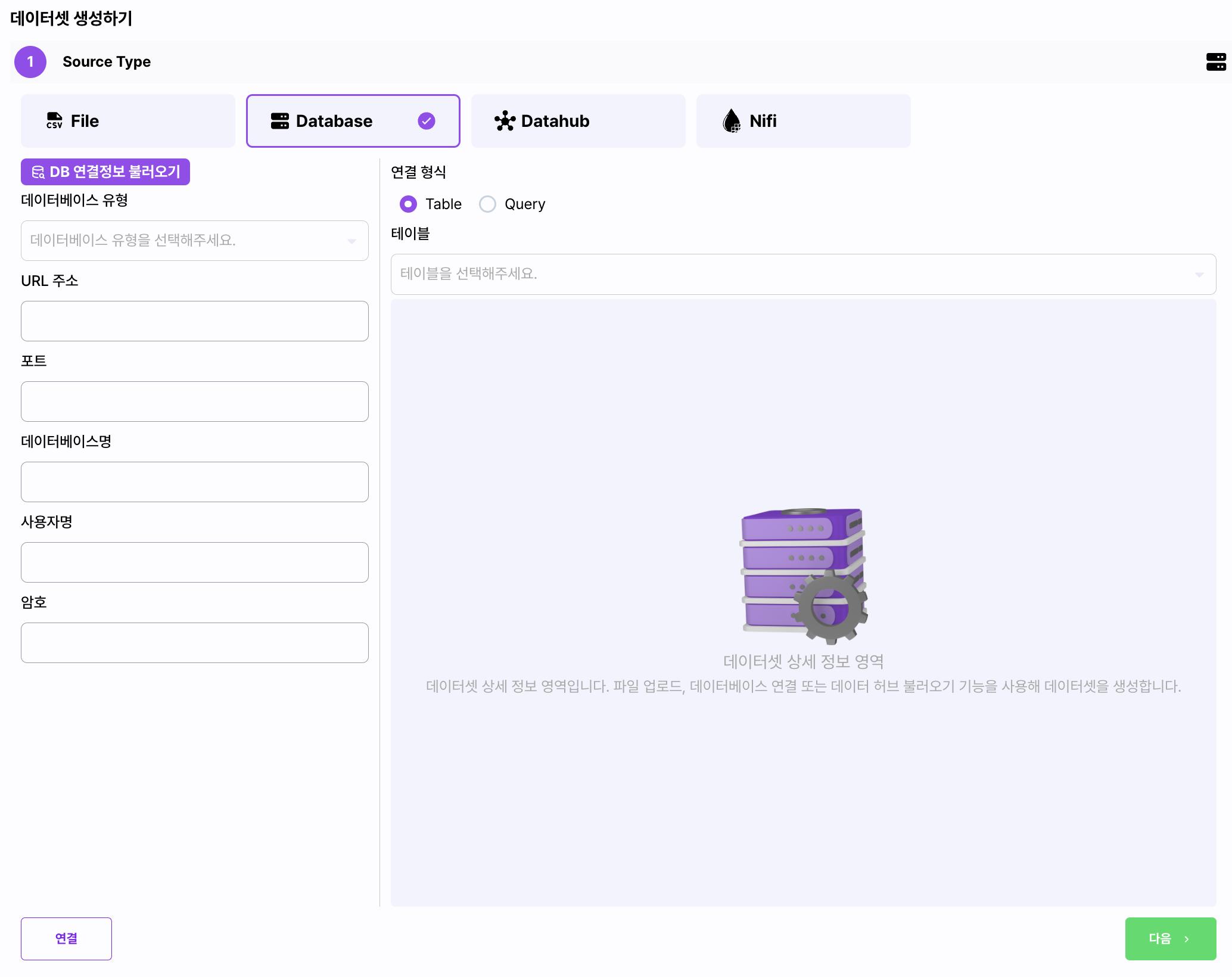
| 필드명 | 설명 |
|---|---|
| 데이터베이스 유형 | 연결할 데이터베이스의 유형을 선택합니다. |
| URL | 연결할 데이터베이스의 주소를 입력합니다. |
| 포트 | 연결할 데이터베이스의 포트를 입력합니다. |
| 데이터베이스명 | 연결할 데이터베이스의 데이터베이스 명을 입력합니다. |
| 사용자명 | 사용자 명을 입력합니다. |
| 암호 | 암호를 입력합니다. |
| 연결 | 입력된 정보로 데이터베이스로의 연결을 확인합니다. |
| Table/Query | 테이블을 선택하거나 Query 입력하여 데이터를 조회합니다. |
| 다음 | 설정한 정보를 이용하여 데이터를 가져옵니다. |
| DB 연결정보 불러오기 | 미리 저장해둔 데이터베이스 정보를 불러옵니다. |
Database를 Source Type으로 선택한 경우, Oracle, MySQL, Mariadb, PostgreSQL 등을 지원합니다.
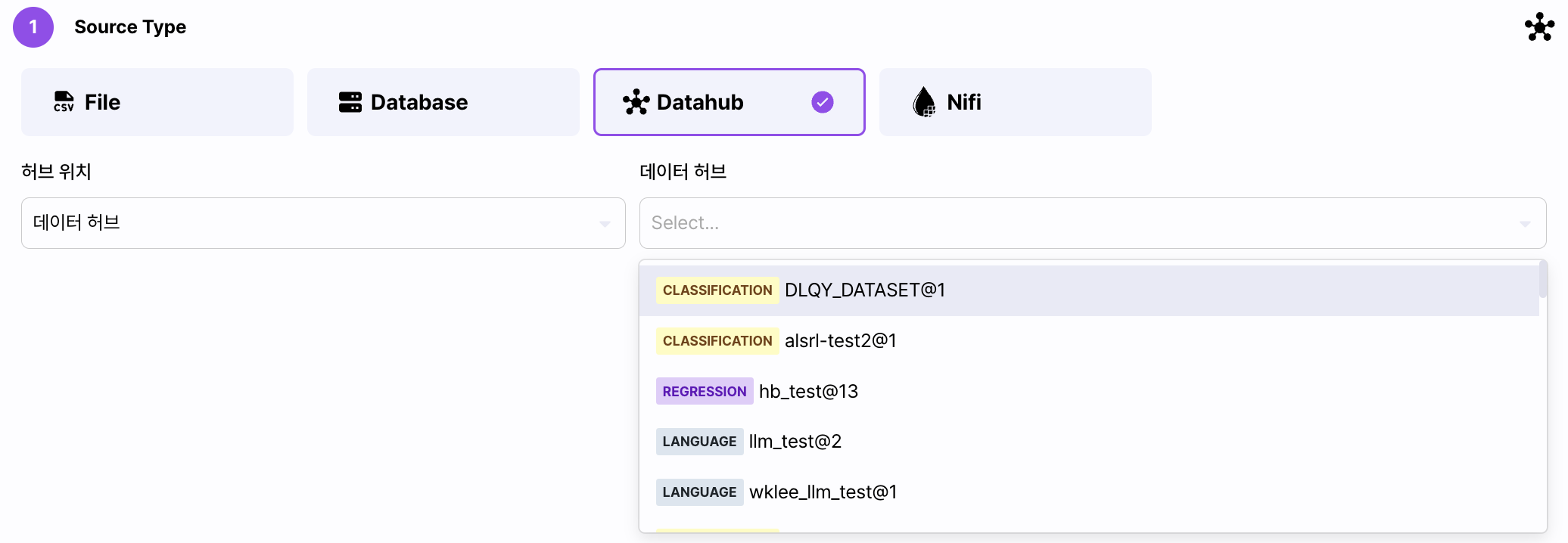
Datahub
- Datahub를 선택하고 등록된 데이터셋을 가져옵니다.
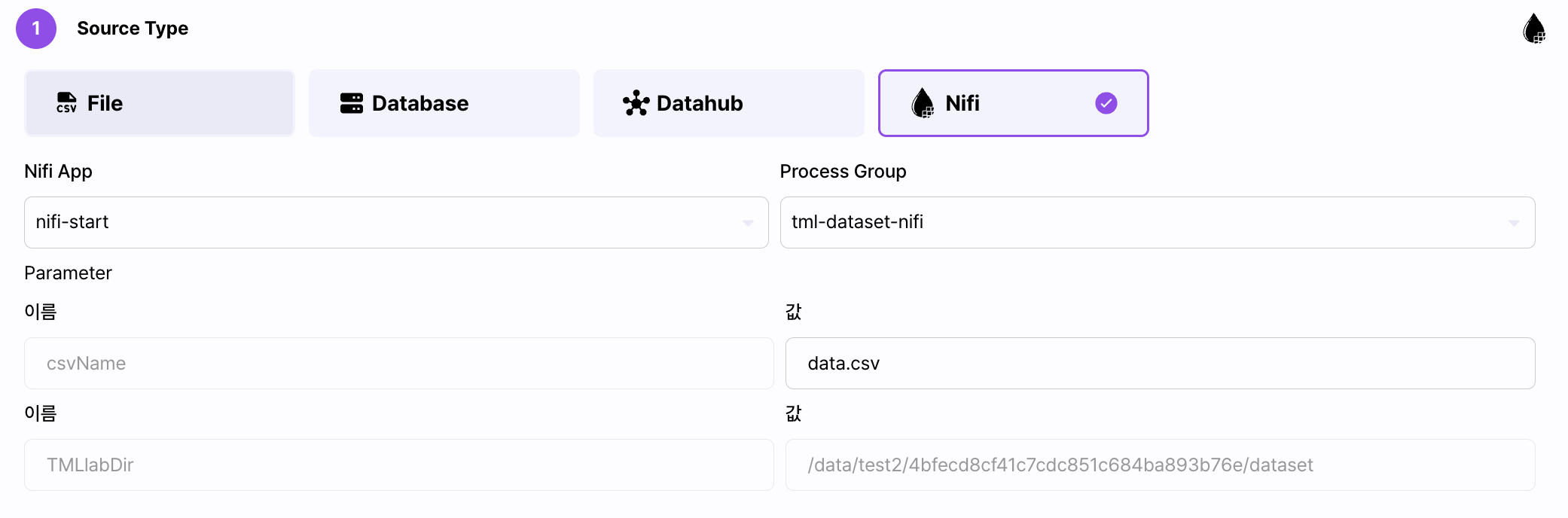
NIFI
- NIFI를 선택하고 미리 생성한 NIFI 앱과 프로세스 그룹을 선택합니다.
대용량 데이터
데이터를 업로드하거나 데이터베이스, 데이터 허브로 불러올 때 현재 사용 중인 어플리케이션의 메모리를 초과하는 데이터를 입력 시
자동으로 대용량 업로드 체크를 진행합니다.
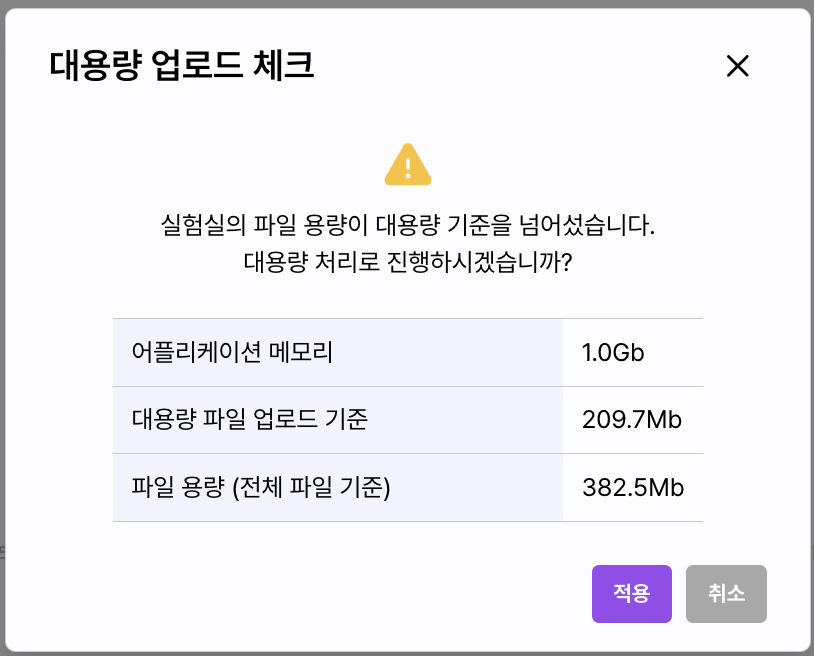

대용량 업로드로 전환되면 실험실의 데이터 타입이 Big Data로 변경됩니다.
데이터 분석과, 학습은 동일하게 진행되지만 지원되는 시각화 차트와 사용가능한 모델이 변경됩니다.
TML의 대용량 처리는 분할 방식으로 지원됩니다. 보유한 시스템 메모리를 초과하더라도 분석과 학습이 가능합니다.
Purpose Type
인공지능의 타입으로 분류(Classification), 회귀(Regression), 군집(Clustering), 시계열(Timeseires) 중 하나를 선택합니다.
기본적으로 데이터셋의 내용에 따라 자동으로 추천되며 변경이 가능합니다.
PurposeType 설명
- 분류(Classification): 데이터를 미리 정의된 범주나 클래스 중 하나로 분류
- 회귀(Regression): 입력 변수로부터 연속적인 수치 값을 예측
- 군집(Clustering): 비슷한 특성을 가진 데이터끼리 그룹으로 묶는 비지도 학습 방법
- 시계열(Timeseires): 시간의 흐름에 따른 데이터 패턴을 분석하고 미래 값을 예측
Target Column
수집한 데이터셋으로 예측하고자 하는 컬럼명을 선택합니다.
기본적으로 수집된 데이터셋의 마지막 컬럼이 자동으로 설정되며 변경 가능합니다.
군집(Clustering) 모델은 비지도 학습으로 타겟 컬럼을 지정하지 않습니다.
Date Column
Purpose Type으로 시계열을 선택할 경우 데이터에서 시간을 나타내는 시간 컬럼을 직접 선택해야 합니다. 데이터셋에 있는 컬럼 중 시간 컬럼으로 사용가능한 컬럼을 자동으로 분류하여 보여줍니다.

데이터 분석
데이터 분석 방법에는 일반 분석, 분할 분석, 샘플링 분석을 지원합니다.
- 일반 분석: 수집한 모든 데이터를 사용하여 데이터를 분석합니다. 데이터셋의 컬럼 수와 로우수에 비례하여 오랜 분석시간이 소요될 수 있습니다.
- 분할 분석: 사용가능한 자원에 맞게 데이터를 분할하여 분석합니다. 분석 학습 모델로 학습하기 때문에 일반 모델과 성능에 차이가 있을 수 있습니다.
- 샘플링 분석: 수집된 데이터의 표본만을 사용하여 데이터를 분석합니다. 학습시에는 모든 데이터를 이용하여 학습합니다.

데이터 분석 방법을 선택하고 생성을 누르면 데이터 분석이 시작됩니다.